《航海王热血航线》ai赋能游戏对战( 二 )
处变不惊:AI已经不再频繁的跑动 , 而是学会了静观其变 , 在关键时刻出手一击 。并且 , 这一阶段的AI学会了位置上的压制 , 可以在移动中逐渐逼迫对手落入竞技场边缘以便最后的攻击
经过不断训练 , AI能够在不断的自对弈中不断提升智能水平 , 发现很多新的技巧 , 逐渐成为一个绝世高手 。然后我们通过延迟操作输出、减少连招次数、降低技能使用概率等手段划分出不同难度的AI , 提供给不同段位的玩家匹配使用 。并且我们也将AI适配到不同的玩法之中 , 比如《航海王热血航线》中的烈焰对决玩法中的噩梦难度AI 。
00:16/00:56Loaded: 100.00%
从一开始的技术突破 , 到后来的在产品中落地使用 , 我们在这过程不断地积累经验、迭代模型、拓宽我们的技术应用 , 让AI能够更好地服务于产品 。我们在打造新手陪玩AI、挫败温暖AI以此提升留存的同时 , 也会继续制作人机挑战AI等全新游戏玩法 , 让玩家体验人工智能的魅力 , 提升玩家游戏的乐趣 。我们会在关注提升竞技性的同时 , 也会更多关注拟人性 , 提高玩家体验 。
数值平衡性测试
数值平衡性对游戏来说 , 也很重要 , 我们在这个应用场景希望解决的问题是 , 不希望出现某个卡牌角色/某组角色组合阵容过于强大 , 出现版本通吃的情况(这会降低玩家对其他角色的养成 , 变相降低游戏收入) , 以及能为策划提供更有力的决策依据 。
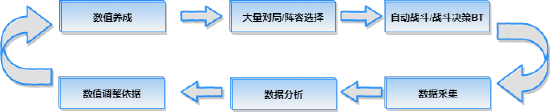
首先 , 回顾一下传统的平衡性测试流程:
文章图片
文章图片
跑大量的对局
这里通常要考虑战前阵容 , 这个数量非常大(全排列4,389,446,880种) , 传统的做法是 , 策划或者测试同学给出一些常见的阵容搭配或者某些搭配规则 , 将全排列数量降至几万种级别 , 然后两两对战100局 。
自动战斗
在跑大量的对局中 , 对战过程需要决策 , 所以一般情况是策划配置行为树(后面简称BT) , 作为战中模拟玩家的决策 。
战中数据记录
我们需要记录每局战斗过程中的关键事件/数据 , 比如击杀、增益buff次数、治疗量、抗伤量等等数据 , 以便后面做数据分析
数据分析
经过上面三部 , 有了大量的对局数据 , 就可以通过数据统计 , 分析出每个角色的一些数据 , 为策划提供决策依据 。
从上面的过程中 , 可以看到 , 有两个地方有一定的弊端 , 一个是阵容选择 , 策划或者测试同学筛选出的阵容 , 未必是真正的强势阵容 , 可能会忽略掉更有潜力的阵容 。二个是自动战斗AI , 使用BT编辑 , 通常策略较单一、简单 , 而无法发挥某些组合的真正能力 。
为此 , 我们希望用强化学习 , 尝试解决上述两个问题 , 因为强化学习就是擅长决策最优选择去实现收益最大化 , 可以打出策划意想不到的套路 。我们分为了两步来进行对比验证:
训练局内对战AI , 来代替BT
结论:【随机阵容+局内AI模型】vs【随机阵容+内置BT】前者平均胜率59% 。这个结论说明AI模型能力要强于BT 。
训练阵容选择AI , 来代替预先固定阵容
结论:【阵容AI模型+局内AI模型】vs【人工筛选强势阵容+内置BT】前者平均胜率96% 。结合第一步结果 , 能说明阵容的重要性 , 且AI更能发挥阵容/角色的能力 。
所以 , 我们使用了这两个模型代替了阵容选择 , 和战中决策BT , 其他过程不变 。在自研的某游戏平衡性测试过程中 , 我们做了个对比 , 发现一个有趣的现象:AI输出的结果中 , 某个定位前排角色 , 胜率较高 , 而传统测试输出他的胜率平平 。后来发现是因为策划在配置BT策略的时候 , 有意的把一些稀缺资源 , 配置给其他角色 , 这样导致战斗过程中 , 这个定位前排的角色 , 拿不到稀缺资源 , 就无法发挥出应有的实力 。
推荐阅读














- 《阴阳师:妖怪小班》即将上线,抓内鬼多是一件美事!
- 《2021年全球移动游戏玩家白皮书》,发掘移动游戏领域与TikTok间的新机遇
- 《英雄联盟》中哪些英雄被改版了?
- 《精英律师》:弱势群体的理论,真的很可怕
- 元气骑士五周年礼包码《元气骑士》五周年版本上线
- 《原神》4星角色培养满意度top8出炉
- 疑似《宝可梦传说阿尔宙斯》御三家偷跑画面截图
- 新作《战神:诸神黄昏》预计2022年推出
- 掀起《歪小子斯科特对抗全世界》热潮的主机游戏
- 《剑网3》新外观抄也抄抄好看的,老是揪着丑东西抄来抄去有意思